Phương pháp Newton và các phương pháp tựa Newton được thảo luận ở đoạn trước rất hiệu quả như một phương tiện để giải quyết các vấn đề tối thiểu hóa không bị ràng buộc. Tuy nhiên, chúng thể hiện khá yêu cầu cao vào dung lượng bộ nhớ máy tính được sử dụng. Điều này là do việc chọn hướng tìm kiếm đòi hỏi phải giải các hệ Các phương trình tuyến tính, cũng như nhu cầu lưu trữ các loại ma trận đang nổi lên. Do đó, đối với những ma trận lớn, việc sử dụng các phương pháp này có thể là không thể. Ở một mức độ đáng kể, các phương pháp hướng liên hợp không có nhược điểm này.
Xét bài toán tối thiểu hóa hàm bậc hai
![]()
với ma trận xác định dương đối xứng A Hãy nhớ lại rằng lời giải của nó yêu cầu một bước của phương pháp Newton và không nhiều hơn các bước của phương pháp định hướng liên hợp cũng cho phép bạn tìm điểm cực tiểu của hàm (10.33) không hơn. hơn các bước. Điều này có thể đạt được thông qua việc lựa chọn các hướng tìm kiếm đặc biệt.
Ta sẽ nói rằng các vectơ khác 0 là liên hợp lẫn nhau (đối với ma trận A) nếu với mọi
Bằng phương pháp hướng liên hợp để cực tiểu hóa hàm bậc hai (10.33), chúng tôi muốn nói đến phương pháp
trong đó các hướng được liên hợp lẫn nhau và các bước

thu được như là một giải pháp cho các vấn đề tối thiểu hóa một chiều:
Định lý 10.4. Phương pháp hướng liên hợp cho phép bạn tìm điểm tối thiểu của hàm bậc hai (10 33) không quá các bước.
Các phương pháp hướng liên hợp khác nhau ở cách xây dựng các hướng liên hợp. Nổi tiếng nhất trong số đó là phương pháp gradient liên hợp.
Trong phương pháp này, hướng dẫn xây dựng một quy tắc
![]()
Vì bước đầu tiên của phương pháp này trùng với bước của phương pháp đi xuống dốc nhất. Có thể chứng minh (chúng ta sẽ không làm điều này) rằng các hướng (10.34) thực sự là
liên hợp với ma trận A. Hơn nữa, các gradient hóa ra trực giao lẫn nhau.
Ví dụ 10.5. Hãy sử dụng phương pháp gradient liên hợp để cực tiểu hóa hàm bậc hai - từ Ví dụ 10.1. Hãy viết nó ở dạng trong đó
![]()
Hãy lấy xấp xỉ ban đầu
Bước đầu tiên của phương pháp trùng với bước đầu tiên của phương pháp đi xuống dốc nhất. Vì vậy (xem ví dụ 10.1)
Bước thứ 2. Hãy tính toán

Vì giải pháp hóa ra được tìm thấy theo hai bước.
Để áp dụng phương pháp này nhằm giảm thiểu sự tùy tiện Chức năng mịn công thức (10.35) tính hệ số được chuyển về dạng
![]()
hoặc để xem
![]()
Ưu điểm của công thức (10 36), (10.37) là chúng không chứa ma trận A một cách rõ ràng.
Hàm được cực tiểu hóa bằng phương pháp gradient liên hợp theo các công thức

Các hệ số được tính bằng một trong các công thức (10.36), (10.37).
Quá trình lặp lại ở đây không còn kết thúc sau một số bước hữu hạn và nói chung, các hướng không liên hợp đối với một số ma trận.
Các bài toán tối thiểu hóa một chiều (10,40) phải được giải bằng số. Chúng tôi cũng lưu ý rằng thường trong phương pháp gradient liên hợp, hệ số không được tính bằng công thức (10.36), (10.37) mà được giả định bằng 0. Trong trường hợp này, bước tiếp theo thực sự được thực hiện bằng phương pháp đi xuống dốc nhất. Việc “cập nhật” phương pháp này cho phép chúng tôi giảm ảnh hưởng của lỗi tính toán.
Đối với một hàm trơn lồi mạnh đối với một số điều kiện bổ sung Phương pháp gradient liên hợp có tốc độ hội tụ siêu tuyến tính cao. Đồng thời, cường độ lao động của nó thấp và có thể so sánh với độ phức tạp của phương pháp đi xuống dốc nhất. Như thực tế tính toán cho thấy, nó kém hơn một chút về hiệu quả so với các phương pháp gần như Newton, nhưng yêu cầu bộ nhớ máy tính được sử dụng thấp hơn đáng kể. Trong trường hợp bài toán cực tiểu hóa hàm với rất một số lượng lớn các biến, phương pháp gradient liên hợp dường như là phương pháp phổ quát phù hợp duy nhất.
Các phương pháp gradient chỉ dựa trên tính toán gradient R(x), là các phương pháp bậc nhất, vì ở khoảng bước chúng thay thế hàm phi tuyến R(x) tuyến tính.
Các phương pháp bậc hai không chỉ sử dụng đạo hàm bậc một mà còn sử dụng đạo hàm bậc hai của R(x) tại thời điểm hiện tại. Tuy nhiên, những phương pháp này có những vấn đề khó giải quyết - tính đạo hàm bậc hai tại một điểm, và hơn nữa, xa mức tối ưu, ma trận đạo hàm bậc hai có thể bị điều hòa kém.
Phương pháp gradient liên hợp là một nỗ lực để kết hợp các ưu điểm của phương pháp bậc một và bậc hai đồng thời loại bỏ những nhược điểm của chúng. Ở các giai đoạn ban đầu (còn xa mức tối ưu), phương pháp này hoạt động giống như phương pháp bậc nhất và ở gần mức tối ưu, nó tiếp cận các phương pháp bậc hai.
Bước đầu tiên tương tự như bước đầu tiên của phương pháp giảm dốc nhất, bước thứ hai và bước tiếp theo được chọn mỗi lần theo hướng được hình thành dưới dạng tổ hợp tuyến tính của các vectơ gradient tại một điểm nhất định và hướng trước đó.
Thuật toán của phương pháp có thể được viết như sau (ở dạng vectơ):
x 1 = x 0 – h cấp R(x 0),
x i+1 = x i – h .
Giá trị α có thể được tìm thấy gần đúng từ biểu thức
Các thuật toán hoạt động như sau. Từ điểm xuất phát X 0 đang tìm kiếm phút R(x) theo hướng của độ dốc (sử dụng phương pháp giảm độ dốc cao nhất), sau đó, bắt đầu từ điểm tìm thấy trở đi, hướng tìm kiếm min được xác định bằng biểu thức thứ hai. Việc tìm kiếm mức tối thiểu theo hướng có thể được thực hiện theo bất kỳ cách nào: bạn có thể sử dụng phương pháp quét tuần tự mà không cần điều chỉnh bước quét khi vượt qua mức tối thiểu, do đó độ chính xác của việc đạt được mức tối thiểu theo hướng phụ thuộc vào kích thước bước h.
Đối với hàm bậc hai R(x) một giải pháp có thể được tìm thấy trong P bước (P– khía cạnh của vấn đề). Đối với các hàm khác, việc tìm kiếm sẽ chậm hơn và trong một số trường hợp có thể không đạt được mức tối ưu do ảnh hưởng mạnh của lỗi tính toán.
Một trong những quỹ đạo có thể tìm kiếm giá trị nhỏ nhất của hàm hai chiều bằng phương pháp gradient liên hợp được hiển thị trong Hình 2. 1.
Giai đoạn đầu tiên. Thực hiện phương pháp gradient
Đặt xấp xỉ ban đầu x 1 0 ,X 20 . Xác định giá trị của tiêu chí R(x 1 0 ,X 20). Đặt k = 0 và chuyển sang bước 1 của giai đoạn ban đầu.
Bước 1.  Và
Và 
 .
.
Bước 2. Nếu mô-đun gradient 
Bước 3.
x k+1 = x k – h tốt nghiệp R(x k)).
Bước 4. R(x 1k +1 , X 2k +1). Nếu như R(x 1k +1 , X 2k +1)< R(x 1k, X 2 k), sau đó đặt k = k+1 và chuyển sang bước 3. Nếu R(x 1k +1 , X 2k +1) ≥ R(x 1k, X 2k) rồi mới vào sân khấu chính.
Sân khấu chính.
Bước 1. Tính R(x 1 k + g, x 2 k), R(x 1 k – g, x 2 k), R(x 1 k , x 2 k + g), R(x 1 k , x 2 k) . Theo thuật toán, từ mẫu trung tâm hoặc mẫu ghép, tính giá trị đạo hàm riêng  Và
Và 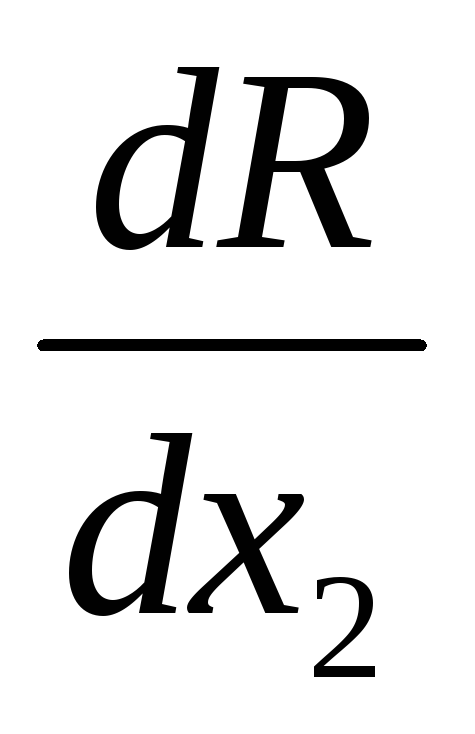 . Tính giá trị mô đun gradient
. Tính giá trị mô đun gradient  .
.
Bước 2. Nếu mô-đun gradient  , sau đó dừng tính toán và coi điểm (x 1 k, x 2 k) là điểm tối ưu. Nếu không, hãy chuyển sang bước 3.
, sau đó dừng tính toán và coi điểm (x 1 k, x 2 k) là điểm tối ưu. Nếu không, hãy chuyển sang bước 3.
Bước 3. Tính hệ số α theo công thức:

Bước 4. Thực hiện bước công việc bằng cách tính toán bằng công thức
x k+1 = x k – h .
Bước 5. Xác định giá trị tiêu chí R(x 1k +1 , X 2k +1). Đặt k = k+1 và chuyển sang bước 1.
Ví dụ.
Để so sánh, hãy xem xét giải pháp cho ví dụ trước. Chúng tôi thực hiện bước đầu tiên bằng phương pháp giảm độ dốc cao nhất (Bảng 5).
Bảng 5
Điểm tốt nhất đã được tìm thấy. Chúng tôi tính toán các đạo hàm tại thời điểm này: dR/ dx 1 = –2.908; dR/ dx 2 =1.600; Chúng tôi tính hệ số α, có tính đến ảnh hưởng của độ dốc tại điểm trước đó: α = 3,31920 ∙ 3,3192/8,3104 2 = 0,160. Chúng tôi thực hiện một bước làm việc theo thuật toán của phương pháp, chúng tôi nhận được X 1 = 0,502, X 2 = 1.368. Sau đó mọi thứ được lặp lại theo cùng một cách. Dưới đây, trong bảng. Hình 6 hiển thị tọa độ tìm kiếm hiện tại cho các bước tiếp theo.
Bảng 6
Quy tắc nhập hàm:
Ví dụ: x 1 2 +x 1 x 2, viết là x1^2+x1*x2Tạo các hướng tìm kiếm phù hợp hơn với hình dạng của hàm đang được thu nhỏ.
Sự định nghĩa . Hai vectơ n chiều x và y được gọi là liên hợpđối với ma trận A (hoặc liên hợp A), nếu tích vô hướng(x, Aу) = 0 . Ở đây A là ma trận xác định dương đối xứng có kích thước n x n.
 .
. ,
,




Ví dụ. Tìm giá trị cực tiểu của hàm số bằng phương pháp gradient liên hợp: f(X) = 2x 1 2 +2x 2 2 +2x 1 x 2 +20x 1 +10x 2 +10.
Giải pháp. Làm hướng tìm kiếm, chọn vectơ gradient tại điểm hiện tại:
|
Phương pháp này được thiết kế để giải quyết vấn đề (5.1) và thuộc lớp phương pháp bậc nhất. Phương pháp này là một sửa đổi của phương pháp đi xuống (đi lên) dốc nhất và tự động tính đến các đặc điểm của hàm mục tiêu, tăng tốc độ hội tụ.
Mô tả thuật toán
Bước 0. Điểm tiếp cận ban đầu được chọn, tham số độ dài bước , độ chính xác của giải pháp và hướng tìm kiếm ban đầu được tính toán.
Bước k. TRÊN k-Bước thứ, mức tối thiểu (tối đa) của hàm mục tiêu được tìm thấy trên một đường thẳng được vẽ từ điểm theo hướng . Điểm tối thiểu (tối đa) được tìm thấy sẽ xác định điểm tiếp theo k xấp xỉ thứ, sau đó hướng tìm kiếm được xác định
Công thức (5.4) có thể được viết lại ở dạng tương đương
![]() .
.
Thuật toán hoàn thành công việc của nó ngay khi đáp ứng được điều kiện; giá trị của phép tính gần đúng thu được cuối cùng được lấy làm nghiệm.
phương pháp Newton
Phương pháp này được thiết kế để giải quyết vấn đề (5.1) và thuộc lớp phương pháp bậc hai. Phương pháp này dựa trên khai triển Taylor của hàm mục tiêu và thực tế là tại điểm cực trị, gradient của hàm bằng 0.
Thật vậy, hãy để một số điểm nằm đủ gần điểm cực trị mong muốn. Hãy xem xét Tôi thành phần thứ của gradient của hàm mục tiêu và mở rộng nó tại một điểm bằng cách sử dụng công thức Taylor cho đến đạo hàm cấp một:
![]() . (5.5)
. (5.5)
Chúng ta viết lại công thức (5.5) dưới dạng ma trận, có tính đến điều đó :
ma trận Hessian của hàm mục tiêu tại điểm ở đâu.
Giả sử ma trận Hessian không phải là số ít. Sau đó cô ấy có ma trận nghịch đảo. Nhân cả hai vế của phương trình (5.6) với từ bên trái, ta thu được , từ đó
![]() . (5.7)
. (5.7)
Công thức (5.7) xác định thuật toán của phương pháp Newton: tính toán lại các phép tính gần đúng bằng k
Thuật toán kết thúc công việc ngay khi thỏa mãn điều kiện
![]() ,
,
độ chính xác nhất định của giải pháp ở đâu; giá trị của phép tính gần đúng thu được cuối cùng được lấy làm nghiệm.
Phương pháp Newton-Raphson
Phương pháp này là phương pháp bậc nhất và được dùng để giải các hệ N phương trình phi tuyến c N không xác định:
Đặc biệt, phương pháp này có thể áp dụng khi tìm điểm dừng của hàm mục tiêu của bài toán (5.1), khi cần giải hệ phương trình từ điều kiện .
Giả sử điểm là nghiệm của hệ (5.9) và đặt điểm gần . Khai triển hàm tại một điểm bằng công thức Taylor, chúng ta có
từ đó (theo điều kiện) nó theo sau
![]() , (5.11)
, (5.11)
ma trận Jacobian của hàm vectơ ở đâu. Giả sử rằng ma trận Jacobian là không số ít. Khi đó nó có ma trận nghịch đảo. Nhân cả hai vế của phương trình (5.11) với bên trái, ta được ![]() , Ở đâu
, Ở đâu
![]() . (5.12)
. (5.12)
Công thức (5.12) xác định thuật toán của phương pháp Newton-Raphson: tính toán lại các phép tính gần đúng với k lần lặp lại được thực hiện theo công thức
Trong trường hợp một biến, khi hệ (5.9) suy biến thành một phương trình duy nhất, công thức (5.13) có dạng
![]() , (5.14)
, (5.14)
đâu là giá trị đạo hàm của hàm số tại điểm .
Trong bộ lễ phục. Hình 5.2 thể hiện sơ đồ thực hiện phương pháp Newton-Raphson khi tìm nghiệm của phương trình.

Nhận xét 5.1. Sự hội tụ của các phương pháp số, như một quy luật, phụ thuộc rất nhiều vào phép tính gần đúng ban đầu.
Nhận xét 5.2. Phương pháp Newton và Newton-Raphson yêu cầu khối lượng tính toán lớn (cần tính toán và nghịch đảo ma trận Hessian và Jacobi ở mỗi bước).
Nhận xét 5.3. Khi sử dụng phương pháp cần tính đến khả năng có nhiều cực trị trong hàm mục tiêu (tính chất đa phương thức).
VĂN HỌC
1. Afanasyev M.Yu., Suvorov B.P. Nghiên cứu hoạt động trong kinh tế: Hướng dẫn. – M.: Khoa Kinh tế Đại học quốc gia Moscow, TEIS, 2003 – 312 tr.
2. Bazara M, Shetty K. Lập trình phi tuyến. Lý thuyết và thuật toán: Trans. từ tiếng Anh – M.: Mir, 1982 – 583 tr.
3. Berman G.N. Tuyển tập các bài toán phục vụ quá trình phân tích toán học: Sách giáo khoa cho các trường đại học. – St. Petersburg: “Văn học đặc biệt”, 1998. – 446 tr.
4. Wagner G. Nguyên tắc cơ bản của nghiên cứu hoạt động: Trong 3 tập. Mỗi. từ tiếng Anh – M.: Mir, 1972. – 336 tr.
5. Ventzel E. C. Nghiên cứu hoạt động. Mục tiêu, nguyên tắc, phương pháp luận - M.: Nauka, 1988. - 208 tr.
6. Demidovich B.P. Tuyển tập các bài toán, bài tập về phân tích toán học . – M.: Nauka, 1977. – 528 tr.
7. Degtyarev Yu.I. Hoạt động nghiên cứu. – M.: Cao hơn. trường học, 1986. – 320 tr.
8. Nureyev R.M. Tổng hợp các bài toán kinh tế vi mô. – M.: NORM, 2006. – 432 tr.
9. Solodovnikov A. VỚI., Babaytsev V.A., Brailov A.V. Toán kinh tế: Sách giáo khoa: Gồm 2 phần - M.: Tài chính và Thống kê, 1999. - 224 tr.
10. Taha H. Giới thiệu về Nghiên cứu Hoạt động, tái bản lần thứ 6: Trans. từ tiếng Anh – M.: Nhà xuất bản Williams, 2001. – 912 tr.
11. Himmelblau D. Lập trình phi tuyến ứng dụng: Transl. từ tiếng Anh – M.: Mir, 1975 – 534 tr.
12. Shikin E. TRONG., Shikina G.E. Nghiên cứu hoạt động: Sách giáo khoa - M.: TK Welby, Nhà xuất bản Prospekt, 2006. - 280 tr.
13. Nghiên cứu hoạt động trong kinh tế: Sách giáo khoa. cẩm nang cho các trường đại học / N.Sh Kremer, B.A. Putko, I.M. Trishin, M.N. Ed. giáo sư N.Sh. – M.: Ngân hàng và trao đổi, UNITY, 1997. – 407 tr.
14. Ma trận và vectơ: Sách giáo khoa. trợ cấp / Ryumkin V.I. – Tomsk: TSU, 1999. – 40 tr.
15. Hệ phương trình tuyến tính: Sách giáo khoa. trợ cấp / Ryumkin V.I. – Tomsk: TSU, 2000. – 45 tr.
| GIỚI THIỆU……………………………………………………............................. ...... | |
| 1. CƠ BẢN CỦA LẬP TRÌNH TOÁN…………. | |
| 1.1. Phát biểu bài toán quy hoạch toán học.................................................. ...... | |
| 1.2. Các loại ZMP……..……..…….…….. .... | |
| 1.3. Khái niệm cơ bản về lập trình toán học.................................................. | |
| 1.4. Đạo hàm định hướng. Dốc…………......................................... | |
| 1.5. Siêu phẳng tiếp tuyến và pháp tuyến ................................................................. .......... | |
| 1.6. Sự phân hủy của Taylor....................................................................................... ............ | |
| 1.7. ZNLP và các điều kiện tồn tại nghiệm của nó.................................................. .......... | |
| 1.8. Nhiệm vụ ……….................................................. ................................................. | |
| 2. GIẢI BÀI TOÁN LẬP TRÌNH PHI TUYẾN TUYẾN KHÔNG CÓ Ràng buộc................................................................ ................................................................. ................................................................. .. | |
| 2.1. Điều kiện cần thiết để giải quyết luật không hạn chế, không hạn chế................................................. ............ | |
| 2.2. Đủ điều kiện Giải pháp ZNLP không có hạn chế.................................. | |
| 2.3. Phương pháp cổ điển để giải ZNLP không hạn chế.................................. | |
| 2.4. Nhiệm vụ................................................................................. ................................................................. ...... | |
| 3. GIẢI BÀI TOÁN LẬP TRÌNH PHI TUYẾN TUYẾN VỚI Ràng buộc BÌNH ĐẲNG....................................... ............................................ ... | |
| 3.1. Phương pháp nhân Lagrange.................................................................. ............. | |
| 3.1.1. Mục đích và cơ sở lý luận của phương pháp nhân Lagrange…….. | |
| 3.1.2. Sơ đồ thực hiện phương pháp nhân tử Lagrange....................................... | |
| 3.1.3. Giải thích hệ số Lagrange................................................................................. | |
| 3.2. Phương pháp thay thế……………………………..................................... ............ ............ | |
| 3.3. Nhiệm vụ................................................................................. ................................... | |
| 4. GIẢI BÀI TOÁN LẬP TRÌNH PHI TUYẾN TUYẾN DƯỚI Ràng buộc BẤT BÌNH ĐẲNG……………………………….. | |
| 4.1. Phương pháp nhân Lagrange tổng quát……………………….. | |
| 4.2. Điều kiện Kuhn-Tucker................................................................................. | |
| 4.2.1. Sự cần thiết của điều kiện Kuhn-Tucker................................................................. | |
| 4.2.2. Sự thỏa mãn điều kiện Kuhn-Tucker.................................................................. | |
| 4.2.3. Phương pháp Kuhn-Tucker....................................................................... . ........ | |
| 4.3. Nhiệm vụ................................................................................. ................................... | |
| 5. CÁC PHƯƠNG PHÁP SỐ GIẢI BÀI TOÁN LẬP TRÌNH PHI TUYẾN TUYẾN | |
| 5.1. Khái niệm thuật toán....................................................................... | |
| 5.2. Phân loại các phương pháp số……………………….. | |
| 5.3. Các thuật toán của phương pháp số……………………….. | |
| 5.3.1. Phương pháp đi xuống nhanh nhất (đi lên)………………………. | |
| 5.3.2. Phương pháp gradient liên hợp.................................................................................. | |
| 5.3.3. Phương pháp Newton................................................................................. ...................................... | |
| 5.3.4. Phương pháp Newton-Raphson....................................................................... | |
| VĂN HỌC………………………………..................................... ............. |
Để biết định nghĩa về hàm tuyến tính và phi tuyến, xem phần 1.2
Phương pháp gradient liên hợp (trong tài liệu tiếng Anh “phương pháp gradient liên hợp”) là một phương pháp lặp phương pháp số(bậc đầu tiên) giải pháp cho các vấn đề tối ưu hóa, cho phép bạn xác định cực trị (tối thiểu hoặc tối đa) của hàm mục tiêu:
![]() là các giá trị của đối số hàm (tham số được kiểm soát) trên miền thực.
là các giá trị của đối số hàm (tham số được kiểm soát) trên miền thực.
Theo phương pháp đang được xem xét, cực trị (cực đại hoặc cực tiểu) của hàm mục tiêu được xác định theo hướng tăng (giảm) nhanh nhất của hàm, tức là. theo hướng gradient (chống gradient) của hàm. Hàm gradient tại một điểm ![]() là một vectơ có hình chiếu lên trục tọa độ là đạo hàm riêng của hàm số theo tọa độ:
là một vectơ có hình chiếu lên trục tọa độ là đạo hàm riêng của hàm số theo tọa độ:
trong đó i, j,…, n là các vectơ đơn vị song song với các trục tọa độ.
Độ dốc tại điểm cơ sở ![]() trực giao hoàn toàn với bề mặt và hướng của nó biểu thị hướng tăng nhanh nhất của hàm và hướng ngược lại (ngược gradient), tương ứng, biểu thị hướng giảm nhanh nhất của hàm.
trực giao hoàn toàn với bề mặt và hướng của nó biểu thị hướng tăng nhanh nhất của hàm và hướng ngược lại (ngược gradient), tương ứng, biểu thị hướng giảm nhanh nhất của hàm.
Phương pháp gradient liên hợp là sự phát triển hơn nữa của phương pháp gốc dốc nhất, kết hợp hai khái niệm: gradient của hàm mục tiêu và hướng liên hợp của vectơ. Nói chung, quá trình tìm cực tiểu của hàm số là một thủ tục lặp, được viết dưới dạng vectơ như sau:
![]()
trong đó dấu "+" được sử dụng để tìm giá trị lớn nhất của hàm số và dấu "-" được sử dụng để tìm giá trị nhỏ nhất của hàm số.
Vectơ đơn vị của các hướng liên hợp được xác định theo công thức:
Có một số cách để xác định giá trị của các hệ số trọng số (biến) được sử dụng để xác định hướng liên hợp.
Phương pháp đầu tiên là xác định hệ số trọng lượng bằng công thức Fletcher-Reeves:

![]() - mô-đun gradient xác định tốc độ tăng hoặc giảm của hàm theo hướng gradient hoặc ngược gradient tương ứng.
- mô-đun gradient xác định tốc độ tăng hoặc giảm của hàm theo hướng gradient hoặc ngược gradient tương ứng.
Phương pháp thứ hai là xác định hệ số trọng số bằng công thức Polak-Ribiere:
Theo các biểu thức đã trình bày, hướng liên hợp mới có được bằng cách cộng độ dốc (ngược độ dốc) tại điểm rẽ và hướng chuyển động trước đó, nhân với một hệ số. Do đó, phương pháp gradient liên hợp tạo ra hướng tìm kiếm hướng tới giá trị tối ưu bằng cách sử dụng thông tin tìm kiếm thu được ở các giai đoạn giảm dần trước đó. Cần lưu ý rằng các hướng liên hợp P, P, ..., P được tính bằng công thức Fletcher-Reeves, cho phép bạn xây dựng các vectơ liên hợp đối với một số ma trận đối xứng cho một hàm cho trước tùy ý.

Quỹ đạo đi xuống trong phương pháp gradient liên hợp (tìm kiếm mức tối thiểu)
Ý nghĩa hình học của phương pháp gradient liên hợp như sau: từ một điểm ban đầu x cho trước, việc giảm dần được thực hiện theo hướng p (gradient hoặc antigradient) đến một điểm x mới, tại đó xác định được vectơ gradient của hàm. Vì x là điểm cực tiểu của hàm theo hướng p nên vectơ gradient của hàm tại điểm x trực giao với vectơ p. Khi đó một vectơ p được xác định là trực giao với một số ma trận đối xứng với vectơ p. Kết quả là việc đi xuống được thực hiện dọc theo hướng đã tìm được đến điểm x mới.

Quỹ đạo chuyển động đến điểm cực trị sử dụng phương pháp giảm dốc nhất (đường đứt nét màu xanh lá cây) và phương pháp gradient liên hợp (đường đứt nét màu đỏ).
Cần lưu ý rằng cứ sau n + 1 bước thì cần phải khởi động lại quy trình thuật toán (n là kích thước của không gian tìm kiếm). Việc khởi động lại quy trình thuật toán là cần thiết để quên hướng tìm kiếm cuối cùng và bắt đầu lại thuật toán theo hướng dốc xuống nhất.
Kích thước bước được chọn từ điều kiện cực tiểu của hàm mục tiêu f(x) theo hướng chuyển động, tức là, là kết quả của việc giải quyết vấn đề tối ưu hóa một chiều theo hướng gradient hoặc phản gradient:
Nói cách khác, kích thước bước được xác định bằng cách giải phương trình này:
![]()
Việc tìm kiếm lời giải tối ưu kết thúc khi ở bước tính toán lặp lại (một số tiêu chí):
Quỹ đạo tìm kiếm vẫn nằm trong một vùng lân cận nhỏ của điểm tìm kiếm hiện tại:
Độ tăng của hàm mục tiêu không thay đổi:
![]()
Độ dốc của hàm mục tiêu tại điểm cực tiểu cục bộ trở thành 0:
Phương pháp gradient liên hợp là phương pháp bậc nhất, nhưng nó có tốc độ hội tụ bậc hai, giống như các phương pháp tính toán Newton. Phương pháp gradient, cùng với nhiều sửa đổi của nó, rất phổ biến và phương pháp hiệu quả tìm kiếm sự tối ưu của đối tượng nghiên cứu. Nhược điểm của tìm kiếm gradient (cũng như các phương pháp đã thảo luận ở trên) là khi sử dụng nó, chỉ có thể phát hiện được điểm cực trị cục bộ của hàm. Để tìm những người khác thái cực cục bộ cần phải tìm kiếm từ những điểm xuất phát khác.
Phương pháp tính toán
Bước 1:Định nghĩa các biểu thức phân tích (ở dạng ký hiệu) để tính độ dốc của hàm

Bước 2: Đặt xấp xỉ ban đầu
Bước 3: Nhu cầu khởi động lại quy trình thuật toán để thiết lập lại hướng tìm kiếm cuối cùng đã được xác định. Do khởi động lại, việc tìm kiếm được thực hiện lại theo hướng đi xuống nhanh nhất.
Bước 4: Tính tọa độ của vectơ đơn vị sử dụng công thức thu được ở bước 1 và xác định tọa độ điểm mới khi di chuyển theo hướng của vectơ đơn vị như một hàm của bước tính toán.
Tính hệ số trọng số và vectơ đơn vị của các hướng liên hợp ở bước tính toán hiện tại (công thức Fletcher-Reeves):
Đối với bước tính toán đầu tiên, hệ số trọng số không được tính toán (hoặc trong trường hợp khởi động lại thuật toán) và vectơ đơn vị của các hướng liên hợp được xác định như sau.











